Threading for Performance
By Kirk J Krauss
When threads in software were introduced, their main purpose was to provide a way for different functions in a program to multitask with one another. Though multiprocessing systems were not very common at the time, threads have since become a primary mechanism for distributing tasks across processors. While threads allow multiple functions in a process to run concurrently, realizing a performance benefit requires more than just splitting some tasks across some threads. The key to effective thread-based multiprocessing is to keep each thread as independent as possible.
This may be easier said than done. True to the original purpose of threads, some degree of multitasking can indeed be achieved just by having two or more threads that do two or more jobs. For example, Thread A can handle input and output tasks via a buffer, and Thread B can transfer data between the buffer and more permanent storage, in an arrangement that might be depicted this way:
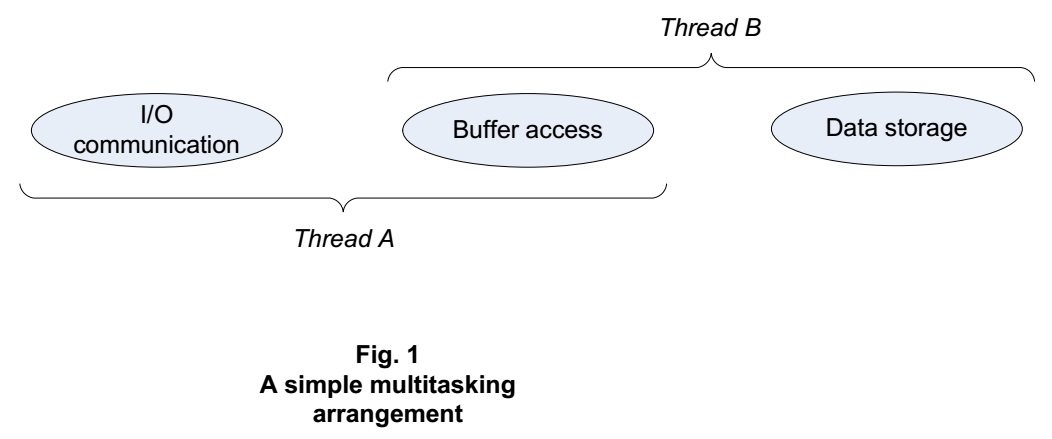
An arrangement like this may improve on single-threaded operation, because in case Thread B becomes busy with data management, Thread A can remain responsive to input and output, and vice versa. But whether this arrangement is optimal for performance on a multi-core computer depends on how much time the two threads need from separate processors, and how much time they can get. These factors have a lot to do with how much time the threads spend waiting on each other.
If both of the threads in the above example are able to write to a shared buffer used for data transfer, then the buffer needs to be protected from concurrent writes that could corrupt its data. The most common form of protection, in a preemptive multitasking system, is a lock, also known as a synchronization object. A thread can acquire the lock as it enters code that performs a write, and it can release the lock afterwards.
There are different types of locks, such as mutexes and critical sections, that are useful in different circumstances. Most locks have these common aspects:
- an atomic operation that either assigns a lock to a thread or makes the thread wait for it,
- a resource that the lock protects, such as memory that’s shared among threads or processes,
- a code sequence that the thread performs under the lock’s protection, and
- an atomic operation that releases the lock, allowing another thread to acquire it.
In the above example, the more time Thread A spends accessing the shared buffer under lock protection, the more Thread B may have to wait to access the buffer, and vice versa. This kind of lock contention can be mitigated in at least a couple of ways:
- limit the code in the sequence under lock protection, e.g. to just the minimum code needed for buffer access, and
- limit the data accessed by each thread while it’s holding a lock, e.g. to just the minimum portion of the buffer that needs updating.
The first way of minimizing lock contention comes naturally to most programmers, who think about concise procedures as a matter of course. The second way may be less commonly considered, but it can be just as helpful for getting each of the available processors to contribute to application performance.
Consider an application whose most significant data is an in-memory dictionary that must be kept up to date. Many threads can access the dictionary, which can be stored in a tree structure. The tree can be organized for searchability, for instance by arranging shorter words or root words near its root, and longer or derivative words branched from the shorter words via links referencing them.
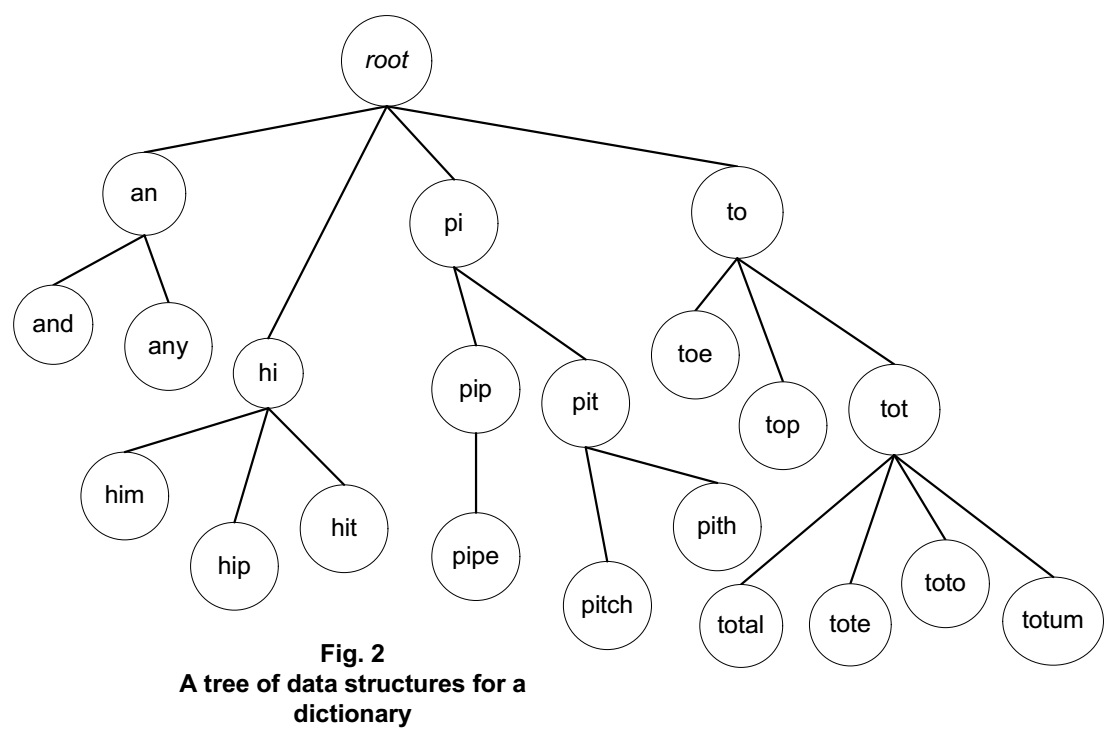
This may be a reasonable way to structure the data in the dictionary, since it sets up a speedy way for a process to sift through the data looking either for an existing word or for a good place to add a new one. But is this structure sufficient, when multiple threads can have that task? How to keep the dictionary both thread-safe and as speedy as can be?
A perhaps overly simple solution might be to place a lock around dictionary lookups, so that if a thread adds a new eight-letter word, the sequence of references leading to that word is sure to remain consistent. The lock allows a thread to find the right place in the tree for the new word and to splice in any needed reference links, all without any other threads intervening or getting confused by data structure changes as those threads go about their own jobs involving the dictionary. To keep the entire tree thread-safe, every thread that accesses the tree must hold the lock.
A single lock around the whole tree effectively limits tree access to a single processor at a time. A limitation like that may not be a big deal if only one processor is available. It can become quite a bottleneck, though, on quad-core (or higher) systems that could benefit from more granular access. The bottleneck can be relieved, even effectively eliminated, if different portions of the tree can be accessed using discrete locks.
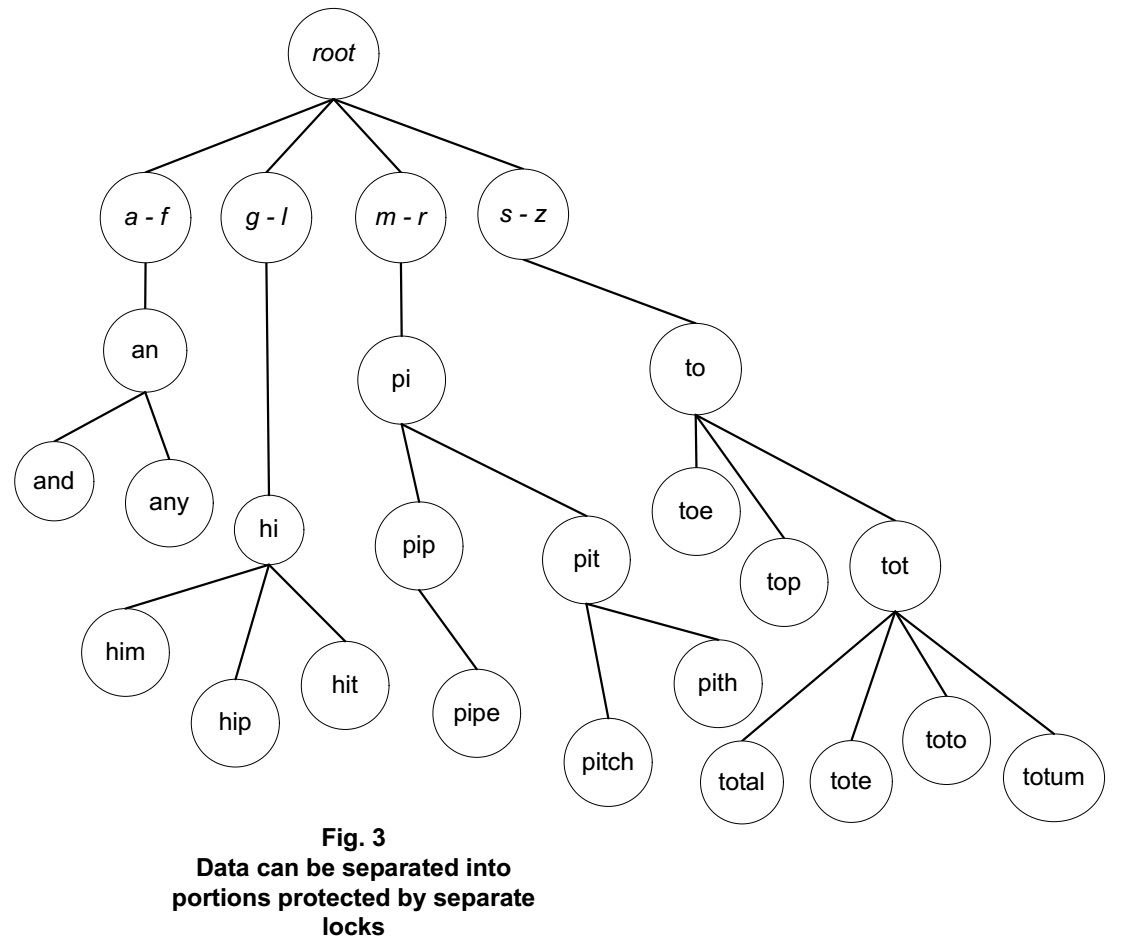
For example, four locks might be made available, each for protecting its own part of the tree. There might be a lock for a sub-tree of dictionary entries for words that start with the letters a through f. Another lock might serve for g through l, and another for m through r, and yet another for s through z. With different portions of the tree covered by discrete locks, there’s a chance for every processor in a quad-core system to safely access data in the tree simultaneously. This still may not often be possible, though, in case dictionary lookups tend to involve one portion of the tree, covered by one lock, more than another.
To further improve the situation, consider these possibilities for protection of large, heavily-accessed data structures:
- cover relatively small portions of the data with discrete locks, so there are more locks than available processors;
- anticipate which portions of the data will most likely need concurrent access, and cover each of those portions with its own lock;
- ensure that the threads that need access to a portion of your data really need access to just that portion, since a need for more than one lock at a time could lead to significant complications; and
- when a “big” lock covering an entire data set is occasionally needed in special situations (e.g. while getting a count of all the items in the set), while “small” locks covering discrete portions of the data set are ordinarily sufficient (e.g. while accessing an individual entry), then acquiring the big lock may need to involve waiting for each of the small locks to be released, and vice versa.
Adjusting Thread Priorities in Real Time
The time a thread spends waiting on a lock is straightforward to check. Just as “getter” and “setter” routines are often used for accessing sensitive data, similar routines can be used for acquiring and releasing a lock. In these routines, you can include code that tracks wait times, for example in thread-local storage or in a shared data structure. The time spent waiting to acquire a lock can be checked on a one-time basis or accumulated, e.g. per thread per lock, across the run.
Tracking lock wait time in a debug build can help you adjust factors such as which portions of a data structure are protected by which lock. Tracking wait times in a release build can give your program a real-time indication of a delay involving a lock. If you’ve done enough homework to allow for some load balancing among the threads, one thing your program can do to reduce wait delays is to adjust a thread’s priority.
Probably the safest thing to do with a thread’s priority, besides leaving it unchanged, is to lower it. On some systems, a process with high-priority threads can hinder other processes. It may even become hard to kill, in case any process trying to kill it is getting starved for attention because of it. If your process is crucial enough to be optimized for best multiprocessor utilization, then it’s probably also crucial enough to be run on an otherwise fairly idle system, so that it gets the least possible interference from other tasks. In that situation, lowering the priority of a lock-hogging thread won’t make your program run any slower. Instead, this may provide other threads with more chances to grab the lock.
Assuming that you have a number of objects protected by a number of locks, how to choose which thread’s priority to lower? This can be determined based on logic that keeps track of wait times and does a little decision making on the way into lock acquisition. A simple data structure for tracking wait times per thread might look like this:
Listing One
// Defines the entry point for the console application.
//
#include "stdafx.h"
#include "windows.h"
#include "stdio.h"
#define MAX_WAIT_FACTOR 3 // Number of attempts to grab lock before acting
#define WAIT_COUNT_THRESHOLD 100 // Number of waits to identify a trend
#define iNumThreads 10 // Normally set by runtime code
// A structure for tracking wait times for a specific critical section.
// Can be extended to track wait times for many or all locks used by the
// process.
//
struct CriticalSectionWaitTime {
HANDLE hThread;
LONGLONG waitTime;
int waitCount;
};
// This line is provided just for example purposes.
// Can obtain iNumThreads by counting CreateThread() calls.
static CriticalSectionWaitTime cswt[iNumThreads];
A structure like this can track wait times for one, several, or all of the locks used by the process. Code that runs at lock acquisition time can accumulate a record of how long each thread waits to acquire the lock. If threads turn out to have imbalanced wait times, such as (for a simple example) a case where one thread’s wait times are much less than the wait times for all the other threads that acquire the lock, then steps can be taken to balance the wait times by making a thread priority adjustment.
Listing Two
// Tracks cumulative wait times for every thread that has waited on the
// critical ction.
//
void UpdateCriticalSectionWaitTime(HANDLE hThread, LONGLONG waitTime)
{
int n = 0;
// Can obtain iNumThreads by counting CreateThread() calls.
while (n < iNumThreads)
{
if (cswt[n].hThread == hThread)
{
cswt[n].waitTime += waitTime;
cswt[n].waitCount++;
break;
}
else if (cswt[n].hThread == NULL)
{
cswt[n].hThread = hThread;
cswt[n].waitTime = waitTime;
cswt[n].waitCount = 1;
break;
}
n++;
}
return;
}
// Searches the set of threads that has waited on the critical section, to
// find the thread with the lowest wait time. Lowers that thread's priority
// iff (a) it's not already been lowered,
// (b) its wait time is considerably less than that of other threads, and
// (c) it's not the current thread.
//
void TryNiceBusyThread(HANDLE hThread)
{
static bool bNoThreadWasNicedYet = TRUE;
LONGLONG lowestWaitTime, nextLowestWaitTime;
HANDLE hThreadWithLowestWaitTime;
lowestWaitTime = cswt[0].waitTime;
nextLowestWaitTime = cswt[0].waitTime;
hThreadWithLowestWaitTime = cswt[0].hThread;
bool bCumulativeWaitsAreSignificant = false;
for (int n = 0; n < iNumThreads; n++)
{
if (cswt[n].hThread == NULL)
{
break;
}
if (cswt[n].waitTime < lowestWaitTime)
{
lowestWaitTime = cswt[n].waitTime;
hThreadWithLowestWaitTime = cswt[n].hThread;
if (cswt[n].waitCount >= WAIT_COUNT_THRESHOLD)
{
bCumulativeWaitsAreSignificant = true;
}
else
{
bCumulativeWaitsAreSignificant = false;
}
}
else if (cswt[n].waitTime < nextLowestWaitTime)
{
nextLowestWaitTime = cswt[n].waitTime;
}
}
if ((lowestWaitTime * MAX_WAIT_FACTOR) < nextLowestWaitTime &&
bNoThreadWasNicedYet && bCumulativeWaitsAreSignificant)
{
if (hThread != hThreadWithLowestWaitTime)
{
DWORD dwPriority = GetThreadPriority(hThreadWithLowestWaitTime);
if (--dwPriority >= THREAD_PRIORITY_LOWEST)
{
SetThreadPriority(hThreadWithLowestWaitTime, dwPriority);
bNoThreadWasNicedYet = false;
}
}
else
{
// Can call out here that the busiest thread is doing a lot of
// waiting.
}
}
return;
}
// Enters a critical section. Calls a function that tracks wait times per
// thread. If a wait is getting out of hand, calls a function that attempts
// to "nice" another thread.
//
void TimedEnterCriticalSection(LPCRITICAL_SECTION cs)
{
LARGE_INTEGER time1, time2;
int retryCount = 0;
QueryPerformanceCounter(&time1);
while (!TryEnterCriticalSection(cs))
{
if (++retryCount == 4)
{
TryNiceBusyThread(GetCurrentThread());
}
Sleep(0);
}
QueryPerformanceCounter(&time2);
UpdateCriticalSectionWaitTime(GetCurrentThread(),
time2.QuadPart - time1.QuadPart);
return;
}
The example code here provides for a simple Windows-specific arrangement. It can adjust one thread’s priority downward, in case that thread is observed to wait for a certain critical section much less than any other thread that acquires it, over time.
Weighing Costs Against Benefits
Breaking down a data set into separate portions protected by distinct locks requires at least some overhead of deciding which lock to grab. Some extra memory also may be required, just for associating a portion of the data set with a lock. The four base branches of the tree shown in Fig. 3 are designated by nodes that can serve primarily to associate each of those branches with its own lock. Splitting the tree this way calls for walking an additional node for every lookup, which may add considerable overhead.
Tracking wait times for a lock, and making real-time decisions based on them, also adds overhead. The amount of overhead depends on how often the need arises to grab the lock. If the lock is one of the locks protecting the tree of Fig. 3, then breaking down the tree into four separately-locked branches, and also tracking lock wait times for each branch, will add both forms of overhead every time the tree is accessed.
Is this overhead worthwhile? One way to think of answering that question is to evaluate worst-case scenarios. Here are a couple of examples.
Scenario 1: If a program does almost nothing but access the tree of Fig. 3 using four threads on a quad-core system, what would happen in case all four branches were protected using a common lock? One thread or another, running on one processor, would have access to the tree, while the other processors would mostly remain idle. As a result, a lot of processing would be available to handle some extra overhead involved managing that processing itself.
Scenario 2: For comparison, what would happen in case each of the four branches of Fig. 3 had its own separate lock, but the overhead of additional branch lookups plus wait time tracking and decision making was four times greater than it would be using the relatively simple, common lock arrangement of Scenario 1? Even if every thread got to run most of the time, in parallel, wouldn’t performance end up about the same? How to know what to expect in a real-world scenario?
Profiling for Multi-Core Insight
The lock wait tracking code introduced above might come to your aid, at this point. If a thread can accumulate the amount of time it spends waiting on a lock, it also can accumulate the amount of time it spends not waiting, which is when it’s doing something arguably useful. If its waiting time exceeds or even comes close to its useful time, then any overhead you’ve added to help it out is probably indeed helping — especially if all your processors are getting plenty of utilization just running your code. But even when you’ve managed to make a thread’s wait times negligible, it’s still true that the only way to know that you’ve got a performance win is to try collecting and comparing timings.
For understanding in depth what happens during an actual run, there’s nothing like using a performance profiler. While no profiler accounts for every nuance involving cache hits or misses, clock speed variability, or instruction pipelining for every line of code, a well-designed profiler can nevertheless give you a reasonable understanding of your code’s execution times. Using the profiler, you can look at time spent waiting for locks, tracking or making decisions about lock usage, and walking through data structures. Comparing the timings provides insight about how useful any performance tweak may be.
Using the profiler, you can check out timings for two runs, where one of them is constrained to a single processor. On Windows systems, to constrain a garden-variety executable so that it runs on just one processor, you can start it with an affinity mask, using a command such as...
start /affinity 0x1 myprogram.exe
To do this with an executable that’s been instrumented using a profiler such as Quantify, first you need an instrumented executable to start. One sequence of commands for running a program with Quantify on a single processor looks like this:
quantify -selective_instrumentation -selected_module_list=myprogram.exe
copy myprogram.exe.QSel myprogram.instr1.exe
start /affinity 0x1 myprogram.instr1.exe
As you compare runs with and without the affinity mask, you can look at time spent waiting both with and without all the cores engaged. Compare that timing difference with the time spent managing locks. This can give you realistic insight about the cost of any decision making about locks used in your application, versus the benefits.
Is there anything more that can be said about the first way of minimizing lock contention mentioned toward the beginning of this article? Certainly, in some situations, parallel access to a certain data structure is less of a problem than, say, pulling together a data set under lock protection and needing to pull off some long-running operation while the lock is still held. If that long-running operation involves calling into system code or third-party code, e.g. via an API function, then a new kind of threat arises: that of possibly somehow re-entering code that relies on the held lock.
As it turns out, this kind of threat has arisen for me on many occasions, and I’ve probably spent more than my fair share of time figuring out solutions for it. But the threat may be better categorized as a thread safety issue, rather than just a matter of performance. Anyway it would be remiss of me to recommend adding locks and threads to your program without discussing thread safety. You can check out my thoughts, here, about the wider range of thread safety matters — along with performance considerations related to each — involving not only re-entrant code but also thread starvation, race conditions, deadlocks, and more.
Copyright © 2017, 2018 developforperformance.com.