Designing the Database of the Future
Toward a high-performance melding of the document-oriented and relational models
By Kirk J Krauss
Tradition has it that database architectures change as the scale of data increases over time. Some of the scale-driven concepts that have gained popularity in recent years include sharding, distributed caching, and streaming database architectures such as Kappa. While these concepts can be useful for databases of practically any type, document-oriented databases that rely on sparse key-value storage may be primed for some scalability enhancements of just their own — or that could also cross over into the territory of relational databases, to realize a mutually beneficial combination. A synergistic melding of these two major database models — document-oriented and relational — could set the stage for a nimbler, faster type of system to become the norm. Of the many possible designs for future database engines, what’s described here is inspired by the basic premise of making more than the best of both worlds. Existing relational databases that migrate to the platform proposed here can become more flexible and configurable than ever before, at the ready to tackle unstructured data in stride, and speedier too. Existing document-oriented databases that make the same migration can gain all the benefits of the relational model without losing any of their simplicity, breadth, or performance.
This discussion starts from the ground up, with some thoughts on a modified form of the general-purpose skip list data structure. A general-purpose skip list is implemented based on the notion that random data will be tracked in the list. But if certain expectations about the structure of a database can be established, then the random element can be swapped for a new kind of skip list arrangement targeting database performance and scalability. This new kind of skip list lends itself to methods that allow for relational-style queries against large document datasets. Having a path toward allowing these queries to readily be applied to most any data at any scale brings to mind ideas for navigating systems as large as the Internet in new and useful ways. Some concepts about how that path might be blazed are explored here.
Talk of data structures for high-performance query processing usually turns to balanced trees or b-trees. A somewhat less well known data structure is the skip list, which in its typical general-purpose form supports search performance similar to that of a balanced tree. Unlike a tree, a skip list requires maintaining data in order. It also requires assigning a level, representing a number of “next entry” links, to each entry individually. Depending on the data, though, maintaining an ordered list with an individual level for each entry may not be a significant price to pay — and with thoughtful design, the investment may really pay off.
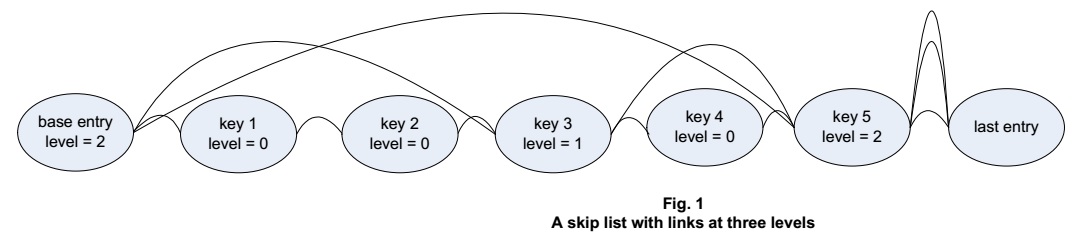
Representing sparse document-oriented tabular data using skip lists can involve a list of lists: that is, one list for keys, and then for each key, an individual list of the values corresponding to that key. Of all the list entries representing values, there could be one entry for each element of each table row. The number of skip lists used to hold an entire table can then be one more than the total number of keys. Assuming each key is a text string, the strings can be ordered alphabetically or by ASCII or other character codes. There can be similar ordering for each skip list of values.
When a row (tuple) is inserted, a search through the skip list of keys will reveal whether a key corresponding to the new row was not present before. In that case, the new key can be added, and a skip list of the values corresponding to that key can be created with just one initial entry for the new row. When a value is added for an existing key, a search through the value skip list for that key will reveal whether a reference count can be incremented for an existing value, or whether the value is new to that list, in which case a new list entry can be added for it. The row can be represented as a set of values linked to a separate skip list in which a unique ID is assigned to every row. Each entry in that unique ID skip list could in turn link to each of the value skip list entries that form the row.
Structures for representing a skip list and one of its entries using C++ might look like this:
Listing One
// This is a simple skip list entry structure. The Key may be a database
// value, if the list is used to store values as opposed to database keys.
// The Key should be of the type coded here in order for the atomic
// operations in the search routines to work properly. The Key can
// alternatively be of a pointer or other type, for use with other atomic
// operations (e.g. InterlockedCompareExchangePointer).
//
typedef struct SkipListEntry {
volatile LONG Key; // Key value for skip list entry
int Level; // Level for skip list entry
SkipListEntry **pNext; // Array of pointers to next entries
} SkipListEntry_t;
// This is a base structure for a skip list. In the code shown in this
// article, the Lock element is used just to protect the header, and the
// list entries themselves are protected via atomic operations coded in the
// search routines. The Lock element also could be used to protect an entire
// list at a time, which may be useful for some platforms or some purposes.
//
typedef struct SkipList {
SkipListEntry *pBaseEntry; // The "first" entry in the list
unsigned int NumEntries; // Number of current entries in list
unsigned int SizeOfEntry; // The size of each entry
CRITICAL_SECTION Lock; // Protects the base list entry itself
void * CreateEntry(int iLevel, unsigned int uSizeOfEntry);
void DestroyEntry(void *pEntry); // Deallocates an entry
void * InsertOrFindEntry(LONG uKey, int iLevel);
void * DeleteEntry(LONG uKey);
SkipList(unsigned int uSizeOfEntry);
~SkipList(void);
} SkipList_t;
Structures for representing a table of keys and values in a skiplist of skiplists might look like this:
Listing Two
// To form a table, one or more skip lists of values are hung off
// corresponding entries in the skip list of keys.
//
typedef struct KeySkipListEntry : public SkipListEntry {
// The key is the skip list key
SkipList *pValuesSkipList; // Skip list of values for a key
} KeySkipListEntry_t;
// There's a unique ID for each row (tuple) and a skip list of unique IDs.
// Each entry in the unique ID skip list has a linked list of pointers to
// all the values for a row. This too could be a skip list, in some
// implementations. Or it could be an array, of the sort that stores links
// from each value skip list entry back to a corresponding row. The skip
// list of keys can have, as its base entry, the skip list of unique IDs.
// This can be set up in the constructor for the key skip list.
//
typedef struct KeySkipList : public SkipList {
SkipList *pUIDSkipList; // Skip list of unique IDs
KeySkipList(int iLevel, unsigned int uSizeOfEntry);
~KeySkipList(void);
} KeySkipList_t;
typedef struct RowEntry {
SkipListEntry *pEntry; // The "first" entry in the list
RowEntry *pNext; // Number of current entries in list
} RowEntry_t;
typedef struct UIDEntry : public SkipListEntry {
// The unique ID is the skip list key
RowEntry *pRowEntry; // Entry in the unique ID list
} UIDEntry_t;
// Each value has a link pointing to an entry in the skip list of unique IDs.
//
#define UID_REF_ARRAY_SIZE 5 // Preallocates some space if > 1
typedef struct ValueSkipListEntry : public SkipListEntry {
// The value is the skip list key
UIDEntry **pUIDEntry; // Array of pointers to unique IDs
unsigned int uUIDs; // Number of rows referencing this value
unsigned int uUIDArraySize; // Number of iUIDs for which there's space
} ValueSkipListEntry_t;
typedef struct ValueSkipList : public SkipList {
// ValueSkipListEntry *pBaseEntry; // The "first" entry in the list
void * InsertOrFindEntry(LONG uKey, int iLevel, UIDEntry *pUIDEntry);
ValueSkipList(unsigned int uSizeOfEntry);
~ValueSkipList();
} ValueSkipList_t;
// A table is built from key-value pairs. The key goes into the key skip
// list. A value goes into the value skip list associated with the key.
// A unique ID is created for each new row (tuple). There's a pointer from
// each value in each value skip list to the entry for the corresponding row
// in the unique ID skip list. There's also a list of pointers from each
// unique ID skip list entry to all the corresponding entries in the values
// list. This sets the stage for fast queries of the sort: "Show me all of
// the rows that have this value for this key".
//
typedef struct Table {
CRITICAL_SECTION *pLocks;
int iNumLocks;
int iMaxLocks;
void InsertRow(std::map‹std::string, std::string› &row,
KeySkipList &Keys);
std::map‹std::string, std::string› SelectRow(int iUID);
void DeleteRow(volatile LONG UID);
Table(void);
~Table(void);
} Table_t
A graphical example of skip lists representing a portion of a table, leaving out for simplicity the interconnections that form the rows, appears below. The links between the skip list entries that are shown and those that are not shown appear as curves that connect skip list entries with points elsewhere along the lines that indicate the overall skip lists. The example table may represent literary works, e.g. in a library.
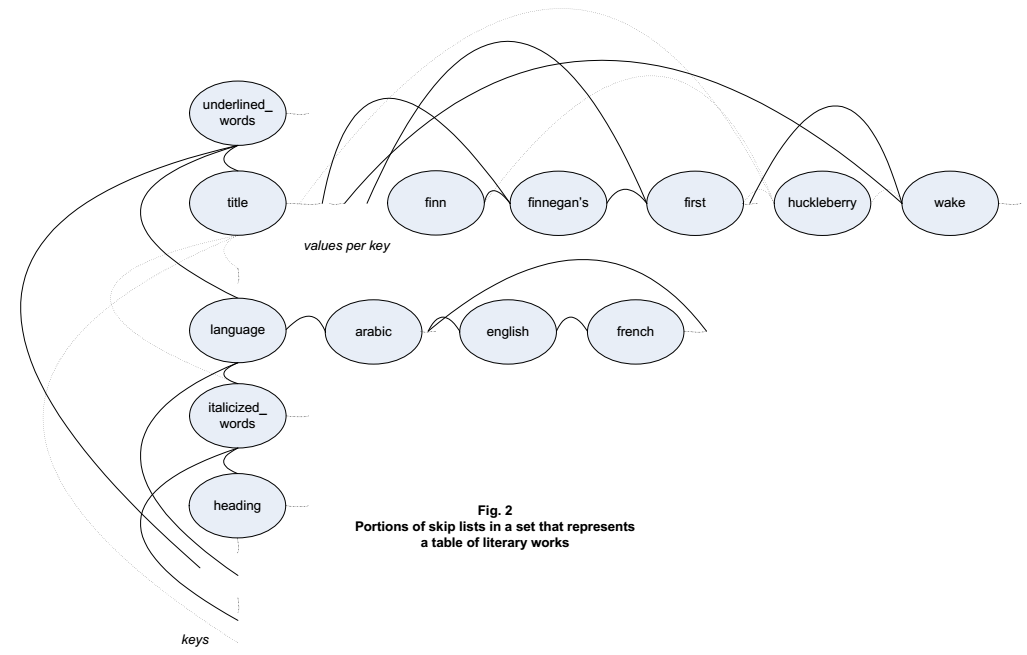
When a book titled “Huckleberry Finn” is inserted, new links are formed, both to connect each term in the book’s title to existing terms that are “previous” along the list, and to also connect those terms to existing terms that are “next”. For each term, multiple links may be added, up to the level chosen for the skip list entry representing the term. The above figure shows these new links as dotted lines.
Creating a skip list entry, of course, depends on first having created a skip list. Some simple skip list constructor code might look like this:
Listing Three
#include ‹iostream›
// Skip list constructor
// Creates a new skip list and returns a pointer to its first entry.
//
SkipList::SkipList(unsigned int uSizeOfEntry)
{
SkipListEntry *pLastEntry;
SkipListEntry **newEntryArray;
// Set up the last SkipList entry. It's not a real entry but rather
// a list terminator.
pLastEntry = new SkipListEntry;
pLastEntry->Key = (unsigned int) LAST_ENTRY;
pLastEntry->pNext = NULL;
// Set up the first entry at the base of the skip list.
this->pBaseEntry = (SkipListEntry *) SkipList::CreateEntry(
/* iLevel = */ 0, sizeof(SkipListEntry));
this->pBaseEntry->Key = 0;
this->pBaseEntry->pNext[0] = pLastEntry;
// Can optionally set up and pool some empty new entries here, for use
// holding real entries between the preconfigured base and last entries.
this->SizeOfEntry = uSizeOfEntry;
this->NumEntries = 0;
InitializeCriticalSection(&this->Lock);
return;
}
How to go about setting up the skip list entries for optimal performance? Answering this question is a matter of considering the factors that make for speedy skip list access. Probably the most important factor is having a sensible mix of levels among the entries.
Random Treatment for Random Data
A discussion delving into skip list construction can’t avoid at least a short foray into the concept of randomness. That’s because a garden-variety skip list doesn’t know which kind of data it will be containing. So for the sake of keeping things generic, most introductions to skip lists describe setting the level for each entry based on one or more random numbers. A well-arranged list has a majority of entries at level 0, considerably fewer entries at level 1, considerably fewer still at level 2, and so forth up the line. This can be arranged using random control, based on code such as my GetTypicallyTrueRandomNumber() routine that can be called over and over to grab random numbers.
Listing Four
// CreateSkiplistEntry()
// Returns a pointer to a skip list entry, including a number of pointers to
// next entries as indicated by the level.
//
// Every entry has a level. A search through the skip list involves walking
// at a given level until the target is reached, or if the target is missed,
// then continuing from the entry before the target, but at the next lower
// level.
//
// If the indicated level is out of range (e.g. -1) then a random level is
// indicated.
//
void * SkipList::CreateEntry(int iLevel, unsigned int uSizeOfEntry)
{
SkipListEntry *pEntry = NULL;
if (iLevel < 0 /* || [CAN ALSO CHECK] iLevel > this->pBaseEntry->Level */)
{
// The new entry will have a random level.
while ((GetTypicallyTrueRandomNumber() % 2))
{
if (++iLevel == this->pBaseEntry->Level)
{
break;
}
}
}
pEntry = (SkipListEntry *) malloc(uSizeOfEntry);
pEntry->Level = iLevel;
return (void *) pEntry;
}
But what’s the performance overhead of doing this on modern systems? The GetTypicallyTrueRandomNumber() routine is useful with the skip lists that support a database implementation. When multiple users are accessing the database, true randomness, wherever it’s possible, may very well be the best randomness.
Note that the code for creating skip list entries, like some of the other code in the listings shown here, allocates space for an entry by calling malloc(). Wherever such a call is made in this and the other listings, a number of items can be preallocated, rather than just one item. This would obviate the need to make some malloc() calls along the way as data is stored. The SkipList structure listed earlier can include a pointer to an array or list of the preallocated blocks. Code for deallocating these blocks is not shown here, nor is destructor code, for the sake of brevity. Careful cleanup is of course necessary for a real implementation to avoid memory leaks.
Turning to the Nonrandom: Why Document-Oriented Data is Special
Is level setting based on random numbers the optimal approach for the document-oriented data that will be going into our skip lists? Might we do better by setting each level based on the data? Remember that for text strings, the skip list Key values, which can represent either keys or values from the table’s perspective, can be alphabetized or ordered by character codes — so the list can be ordered in the usual way for text data. What if the string length serves as the level indicator? What about other considerations like the nesting level in XML or JSON content?
For the large sets of text strings we’re contemplating, setting the level for an entry to be the length of the string represented by that entry may work better, at least within certain limits, than setting random levels. For the value skip lists, that may be effective enough. For the key skip list, we can do even better and assign a level to an entry based on the number of rows that correspond to the associated key. Consider a routine that can insert an entry representing a string in a skip list and that can set the level entirely based on the string’s length:
Listing Five
// Value skip list constructor
// Creates a new skip list and returns a pointer to its first entry.
//
ValueSkipList::ValueSkipList(unsigned int uSizeOfEntry) :
SkipList(uSizeOfEntry)
{
return;
}
// GetSkipListLevelFromStrLen()
// Determines a level for a skip list entry based on the length of a
// character string. This version handles just C-style strings.
//
int GetSkipListLevelFromStrLen(int iLevel, int iMaxLevel, char *theString)
{
int iLevelForEntry = iLevel;
if (iLevelForEntry < 0 || iLevelForEntry > iMaxLevel)
{
// Can interpret the key in other ways, too, e.g. as Unicode chars.
iLevelForEntry = MAX_SKIPLIST_LEVEL - strlen(theString);
if (iLevelForEntry < 0)
{
iLevelForEntry = 0;
}
else if (iLevelForEntry > iMaxLevel)
{
iLevelForEntry = iMaxLevel;
}
}
return iLevelForEntry;
}
// ValueSkipList::InsertOrFindEntry()
// Searches ths list for an entry, and if is it's not there, adds it. This
// form of ::InsertOrFindEntry() also sets up a pointer to an entry in the
// unique ID list. As with other forms of ::InsertOrFindEntry(), a level
// out of range (e.g. -1) indicates that the level should be derived from
// the key. Returns a pointer to the entry.
//
void * ValueSkipList::InsertOrFindEntry(LONG uKey, int iLevel,
UIDEntry *pUIDEntry)
{
ValueSkipListEntry *pEntry = (ValueSkipListEntry *) this->pBaseEntry;
ValueSkipListEntry *pNewEntry = NULL; // New entry (if any)
ValueSkipListEntry *pPrev[MAX_SKIPLIST_LEVEL];
int iLevelForEntry = iLevel;
int iLevelForLink = iLevel;
LONG uLockedEntryKey = LOCKED_ENTRY;
bool bLockedHeader = false;
bool bStoredUIDptr = false;
// Determine the level for the new entry, in case we're creating one.
// This call isn't needed for straight find usage, but it's useful for a
// multipurpose method like this one.
iLevelForEntry = GetSkipListLevelFromStrLen(iLevel,
this->pBaseEntry->Level, (char *) &uKey);
// Find the entry, or if it's new, find where it will fit in the skip
// list. Either way, the search proceeds as though the key has already
// been stored in the skip list.
while (iLevelForLink >= 0)
{
// While the entry is less than the target, go to the next entry.
do
{
if (InterlockedCompareExchange(&pEntry->Key, uKey,
uLockedEntryKey) != uKey)
// ... or on platforms other than Windows, perform atomically:
// while (pEntry->Key < uKey)
{
pEntry = (ValueSkipListEntry *) pEntry->pNext[iLevelForLink];
}
else
{
// Some other thread's at work here; wait and try again.
Sleep(0);
}
}
while (pEntry->Key < LAST_ENTRY);
// Keep links to previous entries.
pPrev[iLevelForLink--] = pEntry;
}
// Let other threads clear out of this part of the list (assuming that
// all threads that access the list are of the same priority).
Sleep(0);
if (pEntry->Key != uKey)
{
// Set up a new value skip list entry and link it to the UID skip
// list entry for the row.
pEntry = pNewEntry = (ValueSkipListEntry *) SkipList::CreateEntry(
iLevelForEntry, sizeof(ValueSkipListEntry));
pNewEntry->Key = uKey;
pNewEntry->pUIDEntry = (UIDEntry **) malloc(
UID_REF_ARRAY_SIZE * sizeof(UIDEntry *));
pNewEntry->uUIDArraySize = UID_REF_ARRAY_SIZE;
pNewEntry->pUIDEntry[0] = pUIDEntry;
pNewEntry->uUIDs = 1;
bStoredUIDptr = true;
// If the skip list's base level is less than the new entry's level,
// update the base level.
if (iLevelForEntry > this->pBaseEntry->Level)
{
// Sync access to the skip list base.
EnterCriticalSection(&this->Lock);
bLockedHeader = true;
iLevelForLink = this->pBaseEntry->Level + 1;
while (iLevelForLink <= iLevelForEntry)
{
pPrev[iLevelForLink++] =
(ValueSkipListEntry *) this->pBaseEntry;
}
this->pBaseEntry->Level = iLevelForEntry;
}
}
if (!bStoredUIDptr)
{
// Link this existing value skip list entry to the UID skip list
// entry for the row. Fill any "holes" that may have been left in
// the array in the wake of past row deletion.
for (unsigned int uUID = 0; uUID < pEntry->uUIDs; uUID++)
{
// Fill the first empty element in the array of UID pointers.
if (pEntry->pUIDEntry[uUID] == NULL)
{
pEntry->pUIDEntry[uUID] = pUIDEntry;
bStoredUIDptr = true;
break;
}
}
if (!bStoredUIDptr)
{
// No rows have been deleted lately.
if (pEntry->uUIDs >= pEntry->uUIDArraySize)
{
// Grow the array of links to row UIDs.
pEntry->uUIDArraySize *= 2;
pEntry->pUIDEntry = (UIDEntry **) realloc(pEntry->pUIDEntry,
pEntry->uUIDArraySize * sizeof(UIDEntry *));
}
pEntry->pUIDEntry[pEntry->uUIDs++] = pUIDEntry;
}
}
if (pNewEntry)
{
// Link the new entry into the value skip list.
for (iLevelForLink = 0; iLevelForLink <= iLevelForEntry;
iLevelForLink++)
{
pEntry->pNext[iLevelForLink] = ((SkipListEntry *)
pPrev[iLevelForLink])->pNext[iLevelForLink];
InterlockedExchangePointer(&((SkipListEntry *)
pPrev[iLevelForLink])->pNext[iLevelForLink], &pEntry);
// ... or on platforms other than Windows, perform atomically:
//((SkipListEntry *)
// pPrev[iLevelForLink])->pNext[iLevelForLink] = pNewEntry;
}
if (bLockedHeader)
{
LeaveCriticalSection(&this->Lock);
}
}
this->NumEntries++;
return pEntry;
}
Suppose we’re using the above routine to populate our table of literary works. A row representing Eric Nylund’s novel titled Halo: First Strike might invoke the above routine once to assign a unique ID to the row and five more times to add entries to the value skip lists including the author’s last name, the year, and three tokenized strings from the title, to arrive at an arrangement something like this one (where just a portion of a set of skip list entries for the table is depicted):
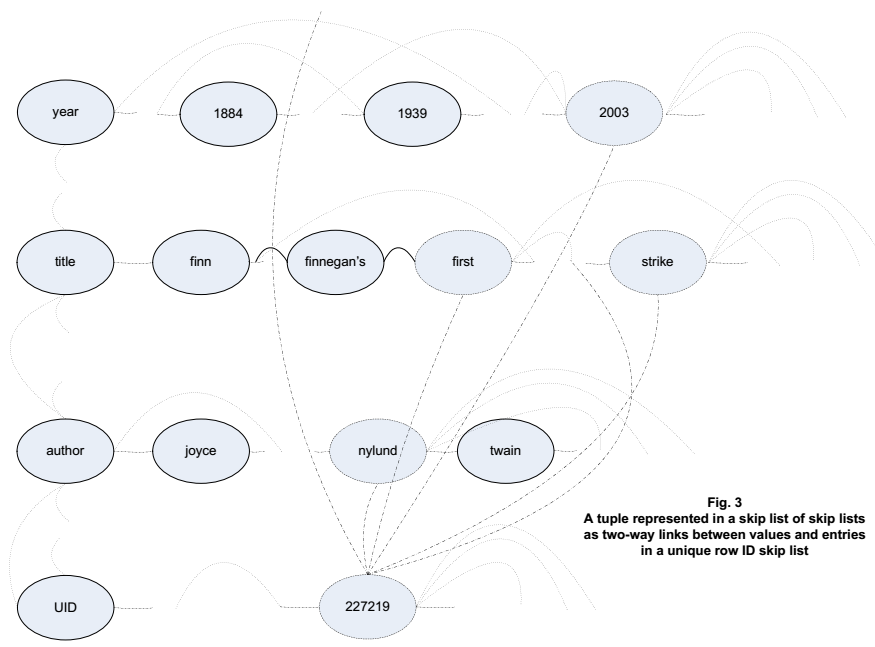
Let’s assume that with the table shown in the above figure, MAX_SKIPLIST_LEVEL is defined to be 4. (In the real world, two-digit skip list levels may be the norm, but we’re keeping this presentation simple.) In that case, we have only a level 0 link between the entries for “finn” and “finnegan’s” because the length of “finnegan’s” is greater than 4. There could be a level 1 link from “finn” to some other element down the line, but adding the “first” token from the title would result in just one link, at level 0, on the portion of the list that includes “finn” and “finnegan’s”.
The distribution of levels among these strings would favor short strings over long strings. If we’re storing two-letter words, then we’ll have at least four levels, one each for two-letter, three-letter, four-letter, and five-plus-letter words. The number of strings increases considerably with string length. Since short words are also used considerably more often than longer words, associating string lengths with levels in a document-oriented skip list could make a lot of sense.
Of course, not all data is alike, and there probably are some situations where nesting level or other factors become more important than word length. A flexible implementation can allow for factors besides a word length corresponding to a skip list entry to define the level for the entry. The ValueSkipList::InsertOrFindEntry() routine of Listing Five (above) has an iLevel parameter to support a variety of use cases. To get the most out of this flexibility, anyone modeling the data would need to be aware to some degree of the properties of the skip lists on which the database depends. The use of skip lists themselves may or may not be advertised. It should be enough to let data modelers know that if they see a pattern that defines how commonly the data items are accessed with respect to one another, and if they can code up this definition so as to quickly choose a numeric value for any item, then they might include that code in a plug-in module that assigns a number to every item as it’s inserted. With this flexibility, old-fashioned level selection based on random numbers is always a possibility, too — no plug-in code required.
Code for finding a skip list entry is included in the ::InsertOrFindEntry() routine of Listing Five. Though the routine doesn’t expect to always find an existing entry identical to the entry to be inserted, it still needs to find the right spot for any new entry. That would be a spot between two existing entries, or between the base and last entries arranged by the skip list constructor.
In Fig. 3 (above), we can see that with the unique ID skip list hung off the base of the key skip list and with the remaining keys alphabetized, finding the list of titles might require just a couple hops down the outermost list — that is, if the list of titles is one of the most heavily populated lists, and if we’ve set levels for the key skip list to account for this popularity as we’ve been progressing. Resetting a level for a skip list element can involve deleting the element and reinserting it at the new level. Or a routine can be written to splice it out and back in using atomic operations similar to those in the ::InsertOrFindEntry() routine listed above.
Finding a row by its unique ID can be as fast as taking a few hops down the unique ID skip list, which can be numerically ordered, then following the links that run from the unique ID skip list entry to the value skip lists to form the row. These links need not each connect to different value skip lists. For any value skip list that contains multiple elements of a row, such as the title tokens “first” and “strike”, the unique ID skip list entry can include links to the several entries in that one value skip list, so that following all the links for a row will retrieve all the row elements.
Deleting a row, such as the row for Halo: First Strike, involves once again finding the “titles” entry in the key skip list, then finding the “halo:”, “first” and “strike” entries among the tokenized title values. With that, we can either delete these title tokens, or decrement reference counts for them. We can then go on to find the “author” and “year” entries in the key skip list and delete or decrement the relevant entries of those lists. Would it be possible to look up the row by finding a value skip list entry for just a particular row value? The above code makes this possible by arranging for the value skip list entries to include links back to the unique ID skip list entry for the row. If we didn’t have these “back links” then all the entries for a row containing a given value would have to be found in two phases: first, by first walking the value skip list to find the row, and second, by walking the unique ID skip list to find the corresponding entry in it.
Targeting to Sync Less Than the Whole Ship (or even a whole on-board library)
The performance achievable via the skip list arrangement we’ve been discussing can be described from more angles than just raw query response rates. First, the lists are walkable by any number of threads, and so they might as well be: even if the database itself has only one calling thread, at least one other thread has at least one other simple job. That is, we want to keep the levels of the key skip list entries up to date according to the populations of values hung off each key. That’s a changeable target, and we don’t know how often to check — so we can just keep a thread going to take care of it for us.
Any thread that sets out to walk a skip list can share time with other threads walking the list, so long as every thread agrees on when to stop and wait. With this style of synchronization, it’s also important for threads of the process working with the lists to have the same priority, so that waiting is sure to give time to threads that need to do something with the list. With that constraint satisfied, atomic operations can be used to synchronize access to skip list entries. A sequence of these operations, starting from the top level down, can progressively protect an entry until any threads walking into it will sit and wait. Once a thread has protected the entry, it can give up a little time so that any other same-priority threads that have been working with the entry have a chance to finish working on it. An agreed value is atomically written into each link leading into the entry, to make this happen.
// Special keys for a skip list
// Can use a datatype with a wider range than "unsigned int" if needed.
//
#define LOCKED_ENTRY ~(unsigned int) 0 // 2 + greatest allowable key
#define ON_DISK_ENTRY (LOCKED_ENTRY - 1) // 1 + greatest allowable key
#define LAST_ENTRY (LOCKED_ENTRY - 2) // 0 + greatest allowable key
// Rule of thumb:
// The larger a skip list can grow, the more levels it can leverage.
//
#define MAX_SKIPLIST_LEVEL 25
Any thread walking the list will wait when it reaches an entry whose key is LOCKED_ENTRY_KEY. When we’re done making updates, we can restore the original key, again via an atomic operation. A waiting thread can then continue walking the list.
There are of course some situations and platforms that call for locks to handle more than little steps through a list. An implementation that synchronizes access to an entire list at once can be based on a critical section such as the SkipList::Lock synchronization object used just for list head protection in the above code. Any code for inserting, deleting, or just finding a list entry can enter the critical section before first accessing the list and can leave the critical section on completion. This also may be needed if multiple tables are going to be accessed per query, such as in a relational arrangement. Still, locking just one list at a time can be less constraining than locking all of the lists comprising a table at once.
Another simple job that’s doable by a dedicated thread is list cleanup. Some tables have rows or elements that expire at some point. A thread can be set up to walk the skip lists checking a time-to-live field. This may take the form of an entry in a time-to-live value skip list, perhaps with one of these entries per row, or it may be a part of an entry in the unique ID skip list or one or more other value skip lists. If each row has a time-to-live field stored in a skip list ordered by that field’s values, then the cleanup thread’s job is as simple as sleeping most of the time and waking up occasionally to delete a bunch of rows linked in toward the list’s end. If this thread is typically sleeping, then its overall activity should detract little from the performance of the rest of the system.
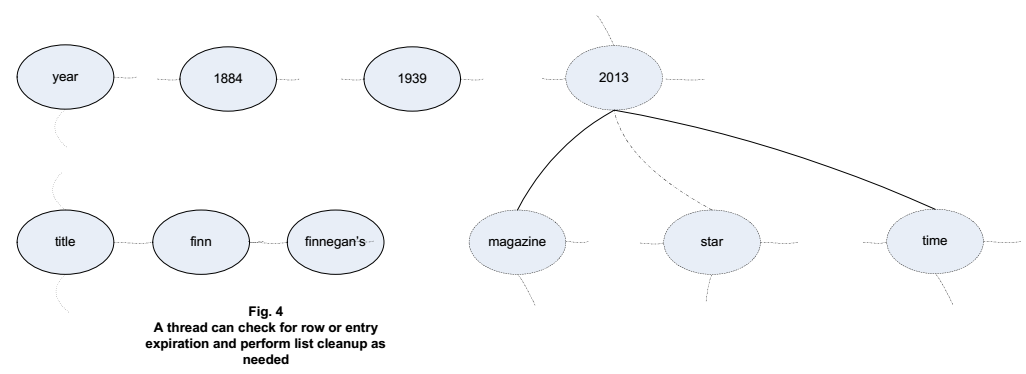
Skip lists are perhaps the ideal data structures for representing and finding data that lies within given ranges. The ordered nature of a skip list makes it easy: find a first element in a range, then get every entry, up to the last element in the range, just by walking through the bottom-level entries. This can make queries of the form SELECT ... WHERE ... IN ... really speedy. But now that we’re talking SQL, why limit ourselves to just range-based queries?
The power of the list-based table structuring described above can really come to the fore when our key/value tables find themselves subject to relational queries. If a table is used to hold relational keys that reference one or more other tables, then the unique ID skip list entry for each row in that table can include links to the value skip list entries in the other tables referenced by those relational keys.
The unique ID skip list entries for the rows of the referenced tables also can include “back links” to the corresponding entries in the table that contains the relational keys. With those additional links, a query against a library database along the lines of “show me the names of everyone who has a book checked out where the title includes the term ‘first’” can work as follows. We first search the key skip list of a Books table to find the key for the “title” entry and get the value skip list for that key. We then find an entry for “first” in that value skip list and follow that entry’s links to all the unique ID skip list entries for the rows containing that value. We next follow any links we find from those unique ID skip list entries to a Checkouts table that has corresponding value skip list entries in it. We finally follow on to a corresponding value skip list entry in a Members table to find the applicable library members and get their names. The entire operation requires only as many memory accesses as are needed to walk one key skip list, one values skip list, and as few as four further links per result.
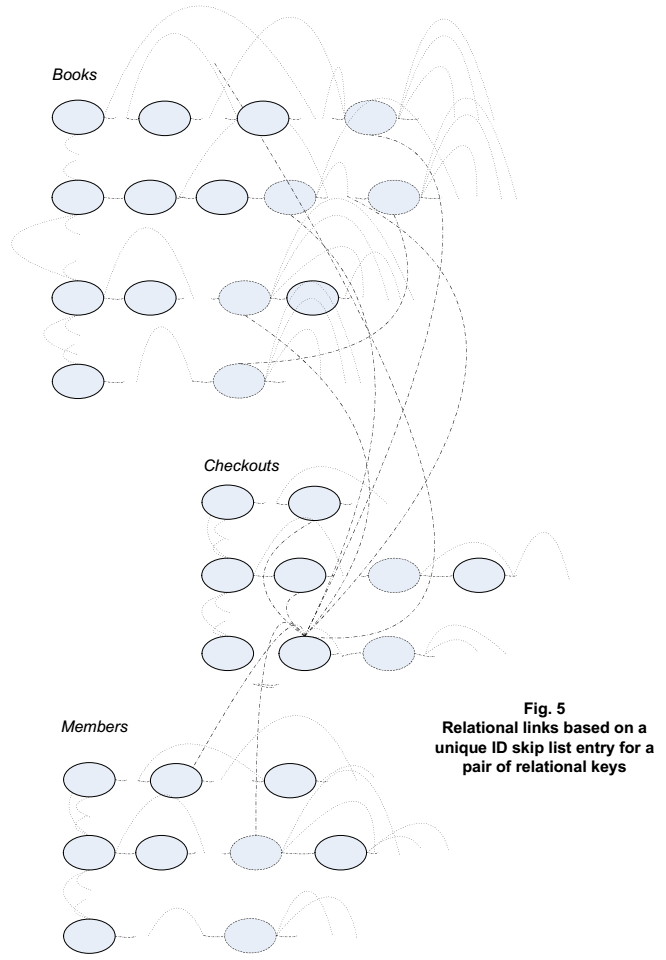
Code for setting up a table for relational queries involving other tables might look like this:
Listing Six
#define MAX_SKIP_LISTS_LOCKABLE_PER_QUERY 64
volatile LONG g_UID = 0; // Global unique ID integer, atomically incremented
// Table::Table()
Table::Table(void)
{
this->iNumLocks = 0;
this->iMaxLocks = MAX_SKIP_LISTS_LOCKABLE_PER_QUERY;
this->pLocks = (CRITICAL_SECTION *) malloc(
this->iMaxLocks & sizeof(CRITICAL_SECTION));
return;
}
// Table::InsertRow()
// Adds a row to a table.
//
void Table::InsertRow(std::map‘std::string, std::string› &row,
KeySkipList &Keys)
{
KeySkipListEntry *pKeyEntry;
ValueSkipList *pValueSkipList(/* iLevel = */ 0);
unsigned int uUID = (unsigned int) InterlockedIncrement(&g_UID);
UIDEntry *pUIDEntry = (UIDEntry *) Keys.pUIDSkipList->InsertOrFindEntry(
(LONG) uUID, /* iLevel = */ -1);
// Find all the value skip lists corresponding to the row.
for (std::map‹std::string, std::string›::iterator itr = row.begin();
itr != row.end(); itr++)
{
// Get the value skip list for a key in the provided map.
pKeyEntry = (KeySkipListEntry *) Keys.InsertOrFindEntry(
(LONG) itr->first.c_str(), /* iLevel = */ -1);
pValueSkipList = (ValueSkipList *) pKeyEntry->pValuesSkipList;
pLocks[this->iNumLocks] = pValueSkipList->Lock;
// Lock the row. When we need more space to remember all the locks
// we're holding as we're progressing, arrange it as needed.
this->pLocks[this->iNumLocks] = pValueSkipList->Lock;
EnterCriticalSection(&this->pLocks[this->iNumLocks++]);
if (this->iNumLocks > this->iMaxLocks)
{
this->iMaxLocks *= 2;
this->pLocks = (CRITICAL_SECTION *) realloc(this->pLocks,
this->iMaxLocks * sizeof(CRITICAL_SECTION));
}
// Add the value for this key.
ValueSkipListEntry *pNewValueEntry = (ValueSkipListEntry *)
pValueSkipList->InsertOrFindEntry((LONG) itr->second.c_str(),
/* iLevel = */ -1, pUIDEntry);
// Link the unique ID skiplist entry for the row to the value skip
// list entry for this key.
RowEntry *pNewRowEntry = (RowEntry *) malloc(sizeof(RowEntry_t));
if (pUIDEntry->pRowEntry)
{
pNewRowEntry->pEntry = pNewValueEntry;
pNewRowEntry->pNext = pUIDEntry->pRowEntry;
pUIDEntry->pRowEntry = pNewRowEntry;
}
else
{
pUIDEntry->pRowEntry = pNewRowEntry;
pUIDEntry->pNext = NULL;
}
}
for (int i = 0; i < iNumLocks; i++)
{
LeaveCriticalSection(&this->pLocks[iNumLocks]);
}
return;
}
Joins can be performed either by implicitly creating tables or by adding links among explicitly created tables. The NULL fields that are inherent in sparse data can be handled in a way that ensures referential integrity, simply by not linking those fields. Star joins and other complex joins can benefit from logic similar to what’s been outlined in the above few paragraphs, where values are linked via straightforward pointer lookups similarly to what we’ve seen for our relatively simple Books, Checkouts, and Members schema, just with more of those links. There can be as many pointer lookups per row, in a join operation, as there are columns represented by values skip lists in the participating tables as indicated by the join parameters.
Taking Care of Business: Cache on Hand, Distribution on the Level
The discussion so far is written as though all the skip lists, complete with all their entries, are always in memory. That need not be the case. It may make more sense to treat high-level list entries as a cache, while saving low-level entries off to disk-based storage until they need to be loaded and accessed. If we’ve done a good job setting levels, then we’ve also done a good job identifying which data to keep in memory and which to leave on disk. The skip list search routines can include a check for an agreed indicator, such as ON_DISK_ENTRY_KEY, and can arrange to load data from disk into memory and to reestablish the needed portions of the skip list that have been stored away.
It may often make sense to cache a row at once, or to store the whole row off to disk at once. Levels for entries in a value skip list, each entry representing one element of a larger row, might serve to determine whether the entire row is cached or stored away. With our library example, for instance, there could be a key associated with values indicating each book’s checkout frequency. The unique ID entry for each book could include a field that references the skip list level for a value associated with that key. The information about any books below a certain level, reflecting checkout frequency, may be stored on disk and pulled back into memory as needed.
As the system scales, more rows can be flushed to disk as memory is filled, or more nodes can be added in a distributed implementation of the database. Disk storage can be in the form of BSON or it can take other forms. Sparse data can be stored in many ways.
A skip list, or a segment of bottom-level skip list entries, stored in XML format might look like a set of skip list KEY fields, each of which is followed by numbers that might represent ordinals, other unique identifiers, or integer offsets. The ordinals or other unique identifiers can reflect absolute skip list positions, or the offsets can reflect relative positions. There would be as many of these values per skip list entry as there are levels for the entry. Reading the skip list’s content back into memory can include creating a map of ordinal-pointer pairs. The entries can be ordered by their ordinals and created with bottom-level links in place as the mapping is built. Then another pass through the list and mapping can replace ordinals reflecting higher-level links with the pointers themselves, to recreate the whole thing. An entire set of tables can be stored and reconstructed using this mapping technique.
Of course, if a skip list can be stored as XML data, it also can be stored in JSON format or in a binary format that can make for better performance in some circumstances. But then there are other circumstances where storing it as XML data is just the thing to do. For instance, IBM® InfoSphere Streams™ supports XML as a native tuple type. Applications that can store their data in XML format can communicate with each other via Streams. For example, the XML data transported via Streams can be arranged in a format suitable for use with IBM® InfoSphere BigInsights™ to make map-reduce analytics combinable with XML-centric applications. Scalable custom analytics solutions based around XML data then come within reach.
XML data is arranged in key-value pairs, where the values can include other key-value pairs, making XML suitable for organizing data in a nested manner. Many applications tend to send XML data that contains repeating keys, such as when the XML data includes key names related to names of certain database table fields. For each table row that is transported via Streams, a set of repeating key names appears in the corresponding XML data. Only the values change from row to row as the data is transported.
BigInsights relies on HDFS, the Hadoop Distributed File System, to support applications that need streaming access to data sets. Tabular data can be stored via HBase, a sparse column-oriented store based on HDFS. HBase’s sparse data organization makes fields that contain NULL free to store, in terms of space.
Can data be transferred in XML format between skip lists in memory and Streams operators that run across any number of nodes? Can those nodes either process the data or save it in HBase format for use with streaming analytics? Why not make both the data and the processing distributable across multiple Streams nodes running on separate computers simultaneously? In a somewhat lossy implementation, any XML data written to HBase can be approximately recreated when it is read back. With additional storage of structural data, the XML data written to HBase can be perfectly recreated in memory.
Reading from and writing to HBase can involve two Streams operators. A first, XML-to-HBase writer operator can discover the structure of XML data and can create and augment that data structure dynamically in memory as further incoming XML data arrives, so it then can automatically and efficiently convert the collected in-memory data to sparse tabular data. A second, HBase-to-XML reader operator can discover the structure of sparse tabular data, and can create and augment that data structure dynamically in memory, so that it can automatically and efficiently be converted to XML data. That data structure could be a set of skip lists as described above.
A Streams operator can construct these skip lists and can fill them with the keys and values represented in an XML stream coming in from HBase. When skip list memory is has filled beyond a certain threshold, or when a save operation is otherwise called for, a Streams operator can store the tabular data in HBase. When an operator is processing an XML stream of unknown length, the data can be captured in chunks and saved off as the threshold is reached. When a key is new, and so unrecognized, it can be added to an existing value skip list, or to a new value skip list associated with a new key. Values associated with that new key can, in turn, be written to a new “column” in the corresponding HBase table.
Thinking Big — the Web as a Bunch of Links
We’ve just seen that with the data model infrastructure described above, frequently-seen values would tend to stay cached in memory as high-level value skip list entries. Terms encountered less often can be stored to disk and loaded as low-level value skip list entries as needed. Data can be distributed across nodes by key. Scalability can be achieved by breaking down a query by key and invoking code on the appropriate node, for example using a Streams operator to walk a value skip list specific to that node.
How big we can scale can depend on the number of nodes. Does this have to in turn depend on the number of keys? Not if an additional data item is used in addition to the key, to select a node. Or there could be a set of nodes per key, each containing a range of values for that key in a skip list. If all the terms that a crawler can find on the World Wide Web were to be stored across a large group of nodes, there could be several nodes for a key, for example a “heading2” key corresponding to the HTML “‹h2›” indicator, where the nodes are queried in parallel. One node might, for example, list terms beginning with the letters ‘w’ though ‘z’ that appear in ‹h2› headings. Another node might list terms in that range that the crawler has found between “‹b›” indicators. Those terms can reside in a value skip list associated with a “bold” key.
With that arrangement, a query such as “show me web pages where ‘pure’ and ‘water’ appear in bold” can get results in short order. Nodes that have ranges of values listed for a “bold” key could walk those value skip lists to find the “pure” and “water” terms. Rows containing these terms can include the URLs where the crawler found them. In response to a query, URLs cached in memory can be returned quickly based on a walk through top-level skip list entries. The user, by paging down in the result set, might cause lower-level entries to appear and might also cause entries to be pulled from disk.
The cached URLs can be those URLs most frequently encountered by the crawler. As the crawler works, it can maintain a reference count per URL, which can be compared with other URL reference counts to determine a skip list level for the URL. URLs of web sites not frequently encountered by the crawler (because relatively few other web sites reference them) can be associated with rows that can get flushed to disk as memory pressure requires. This would allow for the database to scale as queries of more types are made possible, such as queries along the lines of “show me all the sites that have numeric entry fields and the term ‘recalculate’” or “show me all the sites linked by developforperformance.com”. New key skip list entries, along with new value skip lists associated with those keys, can make these queries straightforward to consider and implement.
We’ve seen that tables built on skip lists can be used for scalable key/value storage with fast access and straightforward support for both relational queries and distributed computing arrangements. If this back-end design catches on, who knows, it may become a design of choice for both document-oriented and relational databases. All kinds of systems might get a little faster and more scalable.
Copyright © 2018 developforperformance.com.